Thanks to all who showed up and asked questions!
2023-10-01
Introducing NEMO for the M5Stick C Plus

I've been working on this project for a couple of weeks, and it's pretty close to finished. I've been trying to build some more skills in the embedded systems, microcontroller and Internet of Things realm, and when I decided it was time to expand my experience to ESP32, I wanted a dev kit with a little bit of everything built in. I already have breadboards, displays, servos, sensors, LEDs and accessories galore. I just wanted something cute that'd keep my interest for a while. Enter the M5Stack M5Stick C Plus. Powered by an ESP32, featuring an AXP192 power management unit, accelerometer, IR and red LEDs, a 100mAh battery, microphone, speaker, display, a few buttons and plenty of exposed GPIO pins, it seemed like a good place to start.
My usual method of learning involves sketching out a rough plan for demonstrating mastery of core concepts, so my first few projects were about getting the ESP-IDF and arduino environments working with simple programs. I also ported CircuitPython to it for some of my early projects. I focused on the WiFi stack and designing user interfaces at first, then using UART, SPI and I2C via the GPIO pins.
With most of the tech community excited about the Flipper Zero, I started thinking about what sorts of high-tech pranks one could get away with on a platform like this. The end result is NEMO, named after the titular character in Finding Nemo, in contrast to some other high-tech toy named after a fictional dolphin.
The Stick C Plus has no IR sensor, but it does have a transmitter. Infrared replay attacks might work if you plugged an IR receiver into the GPIO, but I'm not worried about that. I settled for an implementation of TV-B-Gone, relying on previous work by Ken Shirriff and a local hacker, MrARM. I had previously messed with similar projects in both CircuitPython, and at the source-code level, way back in 2008 with the DefCon 16 badge, which also featured an infrared TV killer mode.

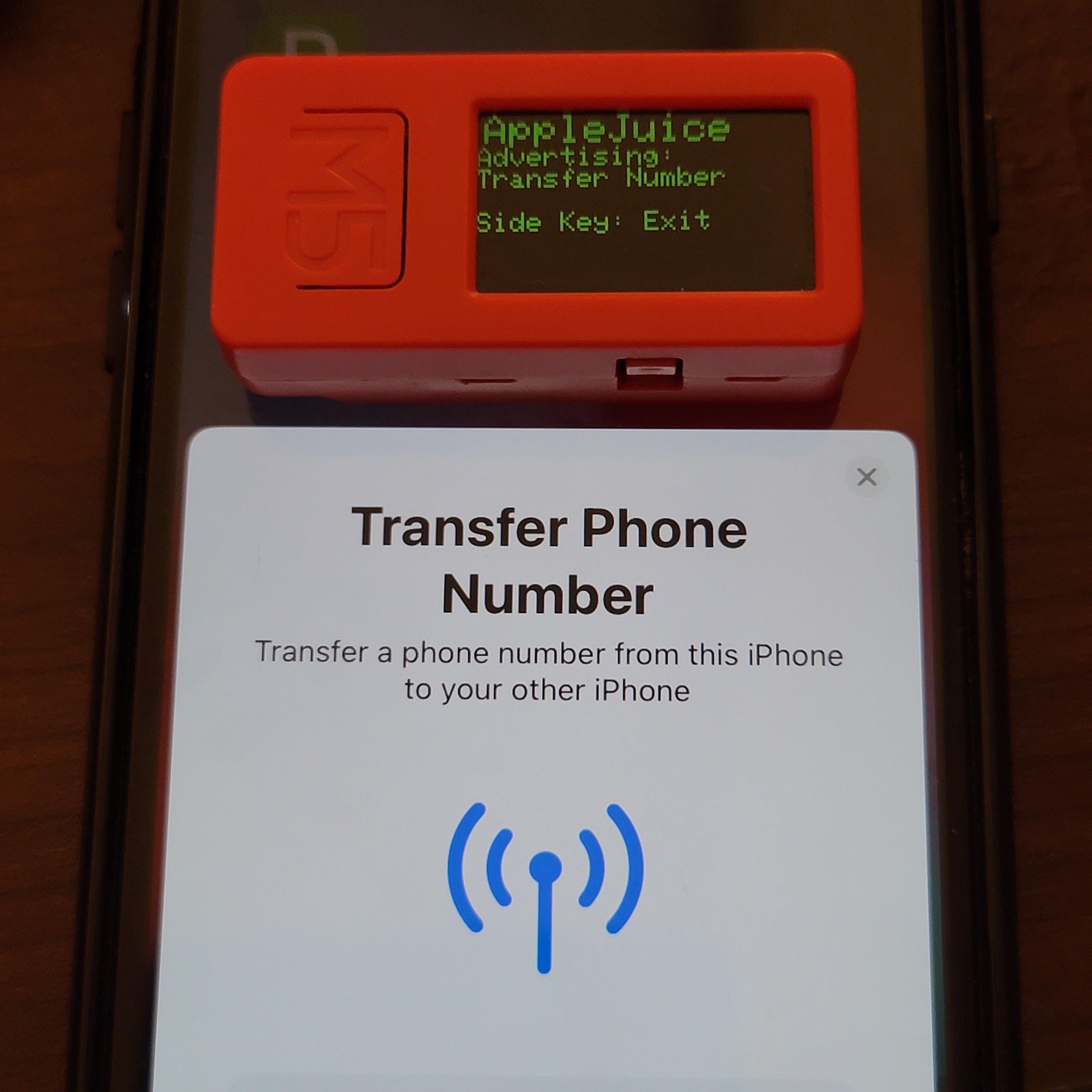
Right about the time I was starting to work on this, DefCon 31 was wrapping up, and a ton of folks were commenting on the bizarre behavior of their iOS devices at the conference, seemingly always displaying pop-ups trying to connect AirPods or other accessories. This became known as the "AppleJuice" attack, and relies on bluetooth low energy beacon advertisements, and iOS's user experience that tries to make device pairing easier. I found a very bare-bones implementation for ESP32, that was somewhat broken. I fixed it and gave it a decent two-button user interface as well.
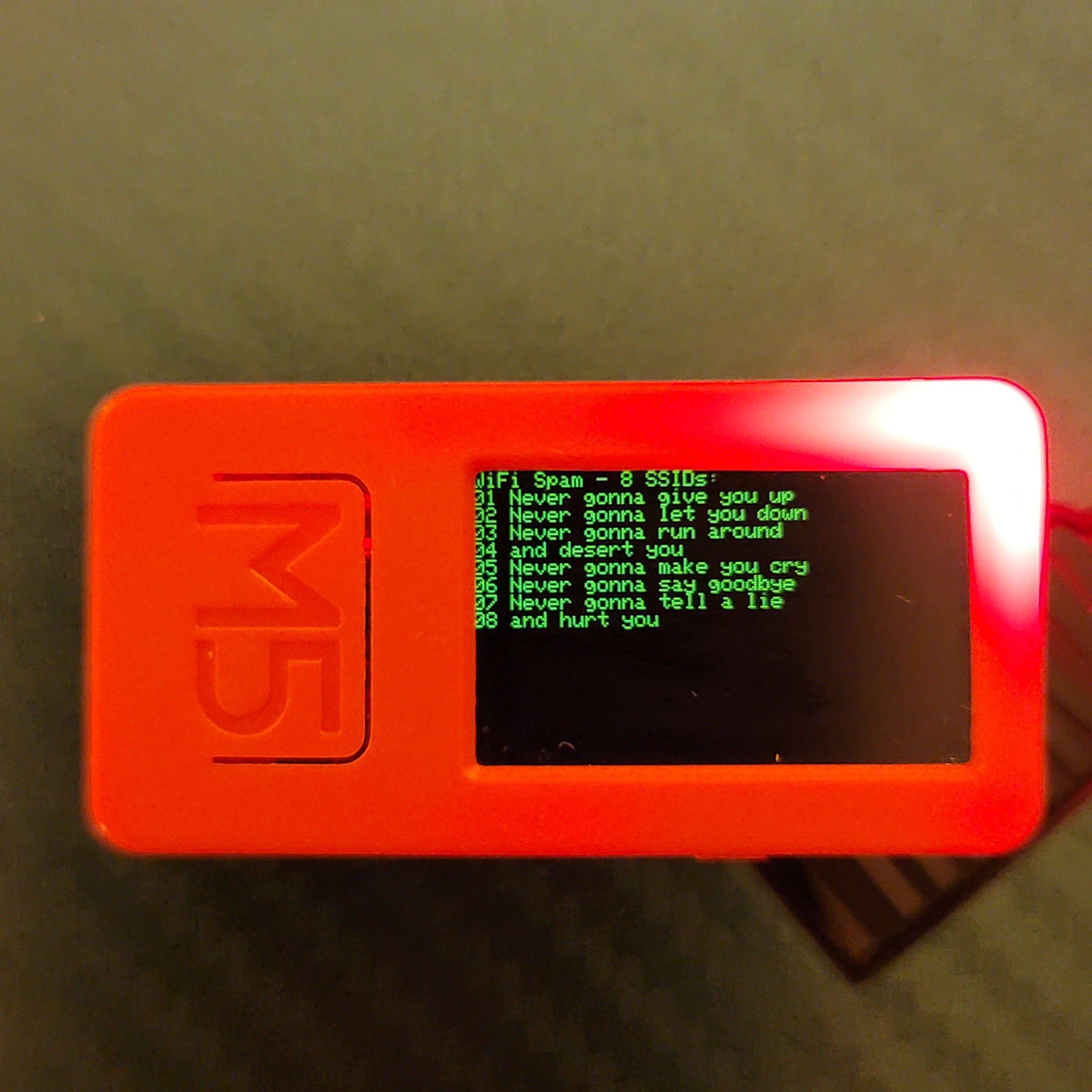
I rounded out the pranks with WiFi Spamming, using a list of funny WiFi SSIDs, the now-popular "RickRoll" SSIDs and a mode that spams hundreds of randomly-named SSIDs per minute.
It defaults to a "watch" mode with a 24-hour clock backed by the on-board real-time-clock. There's a few kilobytes of non-volatile EEPROM storage on board, of which I'm using a few bytes to keep settings like left/right hand rotation, brightness, auto-dimming timer and TV-B-Gone region settings persistent through deep sleep or power off mode. All in all, it's a few existing projects just kind of glued together in a novel way that's easy to use. Those who've known me for a while would say that's on-brand.
A few people have asked me if it's for sale. I have no plans to sell anything, such as M5Stick units pre-flashed with NEMO. This is open-source software I put together for fun, and anyone can use it and extend it. You can buy the device and learn how to load my code on it, but I'd be more excites to hear about people being inspired to build their own cool projects on it.
At $20-$30 depending on the site and accessories you get with the M5Stick C Plus, it has a lot of capabilities. Here's an Amazon Affiliate Link to buy a version with a watch strap, lego mounting and wall-mounting options. The project source code and pre-compiled binaries are up on the m5stick-NEMO GitHub repository, and I am keeping the project up to date in the M5Burner app. You can see a quick walk-through reel on my Instagram as well.
2023-02-25
Running a Kubernetes Cluster with OpenBSD VMM
Kubernetes relies on Linux containers and cgroups, so you can't run Kubernetes or even docker containers directly on OpenBSD, but Alpine Linux runs great under OpenBSD's VMM hypervisor. Alpine shares a lot of the same ideologies as OpenBSD, and it has become a favorite in the Linux container ecosystem.

What's the point?
Kubernetes is a system for deploying containerized applications at scale, in a clustered environment. This lets developers create microservices that run in a mesh configuration, or large, monolithic apps that run in Docker. These docker containers can then be deployed to a kubernetes cluster for testing and production use. In the modern enterprise world, it's becoming far less common to build and provision web servers and run apps on them. More often than not, the infrastructure is virtual, software-defined, and deployed in containers.
It would be far faster and efficient to follow my OpenBSD HTTPD guide and then install Wordpress directly, so this is less about getting wordpress running on OpenBSD than it is about getting one's feet wet in clustered workloads and applying modern DevOps principles in an OpenBSD-centric home lab. Once this is up and running, you can use kubectl, kustomize, or helm to deploy all kinds of things to the cluster with relative ease. I'm gonna try OWASP Juice Shop next.
Caveat Emptor
This is not a good project for someone who’s never used OpenBSD before. I make some assumptions that you’re generally familiar with OpenBSD and performing routine system administration and housekeeping tasks.
This is not a supported configuration. I’ve been running kubernetes on OpenBSD’s VMM hypervisor in my home lab for about 7 months as of the time of writing. I wanted to play with Kubernetes at home, and at the time, my Dell PowerEdge R410 running OpenBSD was the only thing I had available, so I decided to try this out. Occasionally, the network or nodes lag a little, but it’s been pretty stable for the most part.
There are a few limitations to this setup. VMM currently has no way to allocate more than one CPU core to a VM. This causes two problems for Kubernetes:
First is that Kubernetes’ master node minimum requirement is for 2 cores. We can override it, and it seems to run with just one core, but it’s not optimal.
Second is that some workloads may request more than 1 CPU worth of computing resources for a pod. The master node will be unable to find a node that can support that pod, because these worker nodes will only have one core, or 1000 milli-cores, of CPU capacity each. If you see errors like “Unschedulable” and “Insufficient cpu,” this is one potential reason.
VMM Vs. The World
I’ve been running production websites on OpenBSD VMM guests for years without any problems, but I won’t pretend that VMM’s relative immaturity isn’t a deal-breaker for clustered workloads like this. This project was my way of better understanding how kubernetes works under the hood, and an excuse to play UNIX nerd.
Since late last year, I have also been running a similar K8S cluster based on Alpine Linux VMs, but hosting it on slightly better hardware running the ProxMox VE hypervisor. I’m still using the NFS server on my R410, though. ProxMox allows me to allocate 4 cores to each node, so I can run heavier applications. This setup is production-ready and I could justify operating a business on a ProxMox-based cluster like this if I were on a tight budget.
There are commercial solutions that take a lot of the work out of on-premise kubernetes, and affordable options for managed cluster workloads (in the clouds or whatever). Do what makes sense.
Conventions
Commands you should run are in green
File contents are in blue
OpenBSD Host Considerations
Minimum System Requirements
8GB RAM
4-core CPU that has VMM/EPT support (most i5 or i7 CPU should work)
50GB of storage
For this example, we’ll run 3 Alpine Linux VMs – one master node and two worker nodes. Each node will get 2GB of RAM and be set up for 10GB of storage, but qcow2 images only allocate storage when it’s used.
Installing OpenBSD
I make some assumptions about your OpenBSD environment:
A default OpenBSD install with all installsets
/etc/doas.conf is configured so you can use it from a user account you created during the installation. The below is a minimalist doas.conf:
permit persist :wheel
Enough storage for 3 Alpine Linux virtual machines.
I use a 100GB filesystem mounted at /vmm for this
The QCOW2 files in my example lab as of the time of writing are only using about 7GB of storage
Enough storage for the NFS server to support persistent storage for some applications.
I use a 100GB filesystem mounted at /k8s
A full WordPress/MySQL install in k8s is using less than 1GB
You can change these example directories around as you need to, but you’ll see these paths in the documentation.
Networking the OpenBSD host and the VMM Guests
We are going to bridge our guest VMs to the LAN. This is easier if you have multiple ethernet interfaces on your OpenBSD host, but we can work around it if you only have one.
Two ethernet interfaces
On a system with more than one ethernet interface, use a secondary interface to bridge the VMs to the network. In this example, I allowed the installer to configure the ethernet interface bnx0 with dhcp but I also connected the second ethernet interface bnx1 to the network. Set the second interface to come up with no IP address needed.
doas sh /etc/netstart bnx1
–or – Single ethernet interface
If we use a DHCP client on the OpenBSD host, it will intercept all DHCP traffic on the interface and keep the guest VMs from obtaining DHCP leases.
Set up a DHCP reservation for the MAC address of your OpenBSD host. This is only so your router doesn’t issue your IP address to some other system. Configure the OpenBSD host to use the reserved IP address in a static configuration.
An example where my ethernet interface is em0. Static address of this interface is 192.168.1.2. I have marked this IP address as reserved on my home router.
Your static IP details will likely differ from the above. Set appropriately. You may also need to manually configure /etc/resolv.conf
VM Bridge
Add the interface that you’ll be using to bridge0 as in the example below. For my lab machine, I have two interfaces and I’m using bnx1 to bridge my VMs.
Make sure you bring up the bridge interface
doas sh /etc/netstart bridge0
Set up NFS
Kubernetes requires some kind of network-attached storage that all of the containers can access regardless of which worker node they get allocated to. NFS is a popular option, and we’ll eventually install an automated NFS Client storage provisioner on the cluster. We might as well run this on the VMM server itself, since OpenBSD comes with an NFS server in the base install.
Export the /k8s filesystem (with enough storage, as mentioned above) via /etc/exports. You must ensure the network and netmask are appropriate for your LAN.
Each Persistent Volume will invoke a new NFS thread, so we’ll max it out with 20 server threads for NFS and enable both TCP and UDP modes. mountd, portmap, statd and lockd are all part of the RPC and NFS system. Let’s enable them and start the services.
doas rcctl enable mountd
doas rcctl enable statd
doas rcctl enable lockd
doas rcctl enable portmap
doas rcctl enable nfsd
doas rcctl set nfsd flags -t -u -n 20
doas rcctl start mountd statd lockd portmap nfsd
Create Template VM
Directory setup
As mentioned above, this should have plenty of space, at least 30GB. We make it group writable so our user level account (which should be in the wheel group) can use it easily.
doas mkdir /vmm
doas chmod 770 /vmm
cd /vmm
Configure VMD’s virtual switch
Create A very bare-bones vm.conf to set up our bridge network. We’ll add to this later.
Enable and start vmd
doas rcctl enable vmd
doas rcctl start vmd
Download alpine-virt ISO image
ftp https://dl-cdn.alpinelinux.org/alpine/v3.17/releases/x86_64/alpine-virt-3.17.2-x86_64.iso
Create template VM disk image
vmctl create -s 10G alpine-template.qcow2
Boot the template vm
This will start the VM, boot from the iso, and attach your template VM disk image.
doas vmctl start -c -d alpine-virt-3.17.2-x86_64.iso \
-d alpine-template.qcow2 -m 2G -n bridged alpine-template
Install Alpine Linux
Kubernetes works best when there’s no swap, so we’ll disable it with a variable we pass to setup-alpine. Mostly, just follow the prompts.
Log in as root and run the below command
SWAP_SIZE=0 setup-alpine
Specify a hostname (I usually use ‘kube’ but we’ll change it later)
Configure network (DHCP is fine)
Busybox for cron
Create a user-level account
Use Openssh server
Use the vdb disk as “sys” volume
halt
After a while, hit enter. vmctl will exit back to the OpenBSD shell with an [EOT].
Reboot into the template VM
Same command as above but without the installer ISO attached
doas vmctl start -c \
-d alpine-template.qcow2 -m 2G -n bridged alpine-template
Set up the basic software
Log in and immediately elevate to root
su -
Edit /etc/apk/repositories. The default Alpine Linux install only includes vi. If you must, you can use “apk add nano” first.
We only want these 3 repos enabled. You can leave the # in front of the others in the file.
Update the package index and install some software we need:
apk update
apk add doas kubernetes kubeadm docker cni-plugins kubelet kubectl nfs-utils cni-plugin-flannel flannel flannel-contrib-cni docker uuidgen git
We’ll use doas from this point forward. The default configuration of doas should be fine for our purposes (allows wheel-group users to do anything, caches the password for the session). Exit your root shell.
exit
Test doas – this will also cache the password so the rest of the commands run all at once if you just paste them in.
doas id
Paste the below into your terminal if you want. Or type it. I’m not the boss of you.
doas rm /etc/ssh/*key*
printf "#!/bin/sh\nmount --make-rshared /\n" |\
doas tee /etc/local.d/sharemetrics
doas chmod +x /etc/local.d/sharemetrics
doas rc-update add local
doas rc-update add docker default
doas rc-update add containerd default
doas rc-update add kubelet default
doas rc-update add rpc.statd default
doas rc-update add ntpd default
echo "net.bridge.bridge-nf-call-iptables=1" | doas tee -a /etc/sysctl.conf
doas apk add 'kubelet=~1.26'
doas apk add 'kubeadm=~1.26'
doas apk add 'kubectl=~1.26'
The last 3 commands ensure we don’t let Kubernetes components get upgraded past the minor version we specify. Replace 1.26 with the current minor version (1.22.3-r1 would be 1.22). As of writing, 1.26 is the latest. This keeps the cluster nodes from inadvertently updating to a higher version with incompatibilities.
Shut down the system. This has most of what we need for all the kubernetes nodes.
doas halt
Once vmctl exits and you are back at the OpenBSD shell, make this template disk image read-only. This will be our base image for the 3 Alpine Linux VMs, and if something changes in this file, it’ll break the derivative images.
doas chmod 400 alpine-template.qcow2
Clone Template VM
Create the derivative images for the master node and two workers.
doas vmctl create -b alpine-template.qcow2 kube-master.qcow2
doas vmctl create -b alpine-template.qcow2 kube-w1.qcow2
doas vmctl create -b alpine-template.qcow2 kube-w2.qcow2
Add them to /etc/vm.conf. We specify MAC addresses inside the interface clause because if we don’t, they will get a different random MAC address (and probably IP address) at runtime. My /etc/vm.conf now looks like this:
Before we continue, it’s a good idea to set up a DHCP reservation for the MAC address you use for the master node. If the master node IP changes, the workers can’t find it, and fixing the cluster is not a very straightforward task. This isn’t too important if you’re just playing around with kubernetes for fun, though.
If you have more than 8GB of RAM, I’d allocate about 25% of your RAM to each VM. 16GB of RAM? 4096M per node. 32GB of RAM? Give each node 8192M.
If you have a system with more than 4 cores, and more than 32GB of RAM, consider adding more worker nodes and tuning the RAM on them. 2GB per node is an absolute minimum and will lag a lot.
Reload the configuration and start up the master node with a console
doas vmctl reload
doas vmctl start -c kube-master
Bootstrap the master node
Login to the console or SSH into the master node.
Set the host name and machine-id
These are important for the k8s networking components.
echo "master" | doas tee /etc/hostname
doas hostname -F /etc/hostname
uuidgen | doas tee /etc/machine-id
Install k8s management tools
doas apk add k9s helm curl
Initialize Kubernetes
Here, we have to work-around the requirement for two CPU cores.
doas kubeadm init --ignore-preflight-errors=NumCPU \
--pod-network-cidr=10.244.0.0/16 --node-name=master
This could take some time to pull images and generate crypto keys. It will eventually spit out a bunch of stuff including the below (slightly modded).
Execute these with your user-level account on master.
mkdir -p $HOME/.kube
doas cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
doas chown $(id -u):$(id -g) $HOME/.kube/config
The initialization will also show the command to join nodes to the cluster...
kubeadm join 192.168.1.xxx:6443 --token foobar.foobarfoobarfoob \
--discovery-token-ca-cert-hash sha256: \
d34db3efd34db3efd34db3efd34db3efd34db3efd34db3efd34db3efd34db3ef
Save this kubeadm join command. You'll need it for all your workers. I create a file on master and save it just so it’s easy to find.
Install Flannel CNI plugin.
This is technically the first package you manually deploy to your cluster. It creates a daemonset of containers (pods) that will self-replicate across all nodes as they join the cluster.
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
Worker Nodes
Boot up the first worker node. On your OpenBSD VMM host, run:
doas vmctl start -c kube-w1
Login to the console or SSH into this worker node.
Set the host name and machine-id
Similar to how we set up the master node, we need each worker to have a unique name and machine-id
echo "kube-w1" | doas tee /etc/hostname
doas hostname -F /etc/hostname
uuidgen | doas tee /etc/machine-id
Run the command to join the cluster as provided when initializing the master node. Don’t forget to use doas.
doas kubeadm join 192.168.1.xxx:6443 --token foobar.foobarfoobarfoob \
--discovery-token-ca-cert-hash sha256: \
d34db3efd34db3efd34db3efd34db3efd34db3efd34db3efd34db3efd34db3ef
Kubernetes tokens are only valid for 24 hours. If you want to join a new worker to the cluster, you can generate and print a new join token at any time. You must execute this on the MASTER node, then run the output of this command on your new worker node.
kubeadm token create --print-join-command
That’s it. Log off. You're done with this worker node.
You can hit enter and then use the “tilde period” escape sequence ~. to break out of the vmctl console while the VM remains running. If connected to your VM server over SSH, note that ~. is also the sequence to terminate your SSH session, so use ~~. instead.
Rinse, Repeat
Repeat the above process for kube-w2 (make sure you change the hostname in the commands above) before you continue. You can repeat this process to make as many worker nodes as you have the resources for. You’ll need to make new drive images and VMs in /etc/vm.conf to support them.
Behold, your Kubernetes cluster
Login to the master node again.
Basic kubectl commands
kubectl get nodes
kubectl get pods --all-namespaces
You should see stuff running.
K9S Navigation
K9S is a curses-based Kubernetes UI. Just run “k9s”
If k9s exits with an error message, it may be due to your termcap being unsupported. Try the below command, then run k9s again. If that works, consider adding this to the .profile file so it runs every time you log in.
export TERM=xterm-256color
":" will let you jump to the various pages. Some pages worth knowing:
node - all connected nodes
deploy - deployments, which configure pods and replicaSets
daemonset - daemonsets - groups of pods that should run on many nodes
statefulset - Stateful applications
pods - Individual containers
namespace - namespaces in the cluster
On each page, note the hotkey menu at the top. You can also use "/" to search the current content of the given page. You can on-the-fly edit a manifest of a deployment, for example, or delete a pod to evict it (usually results in a restart which may or may not be on the same node) - Also pay attention to the number hotkeys which let you filter by namespace. Often, you'll want 0 for ALL namespaces
Troubleshooting with K9S
Cursor over an asset (like a pod, daemonset, deployment) and use “d” to describe the asset. You can usually see information about what’s going on. This is useful for figuring out why a pod is in a CrashLoopBackoff state.
Use “l” (lowercase L) to fetch logs. You may need to use the hotkeys to view head or tail the logs, adjust line wrapping, etc.
Use “e” to edit a manifest on-the-fly. You can often “hack” quick fixes in if something is typoed or you want to scale up a deployment manually.
Use “s” on a pod to try to get a shell on the container. Some containers do not support shells. Containers that are crashing will not remain up long enough to do anything meaningful in a shell.
Provision NFS Storage
SSH back into your MASTER node.
When an application requires storage, it makes a “Persistent Volume Claim.” These will lurk around forever and stop the application from deploying until a persistent volume is created that meets the criteria for the claim. In a managed cluster, this happens automatically, so we’re going to deploy our own magic process to create these volumes on the fly, using storage we provide via NFS.
For this, we will use nfs-subdir-external-provisioner, and set up Kustomize to tweak it for our environment. Kustomize can modify and patch stock manifests so you don’t have to edit them directly – and as you’ll see here, sometimes you don’t even need to download them, you can just reference the repository.
Make a directory
Generally speaking, we work in a directory for a given task. We’ll make a new directory for our storage provisioning.
mkdir storage; cd storage
Create configuration files
Create the below files inside the storage directory with the contents as shown. YAML is extremely picky and your browser might not copy/paste these correctly. You can snag all of the YAML files I use in this example from my github: n0xa/k8s-playground
Be sure to modify the highlighted values in the patch file to match your NFS server’s details.
Deploy with Kubectl
This will use the kustomization.yaml to patch the manifest files, and apply the resulting assets to your cluster.
kubectl apply -k ./
Deploy MetalLB Load Balancer
Now we need to build a load balancer to expose the service to an external set of IP addresses. We will use MetalLB for this. We are going to arbitrarily use some LAN IP addresses here. In my home lab, the range 192.168.1.1 through 192.168.1.63 is out of the normal DHCP scope. You may wish to set aside a range of addresses that aren’t managed by DHCP at all.
Make a directory
mkdir ~/metallb; cd ~/metallb
Install MetalLB with kubectl
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.13.7/config/manifests/metallb-native.yaml
Configure Load Balancer IP Addresses
Create a configuration yaml for the IP addresses you’re reserving for the load balancer. You can specify IP address ranges, CIDR blocks or single IPs if you want. You can add as many lines as you wish. You can see I defined two IP address ranges, one named “production” and the other (which is technically one IP address) named “wordpress”
Apply the configuration
Note that the API extensions this manifest references won’t be available until after the MetalLB resources are all up and running.
kubectl apply -f address.yaml
By default, any new service that gets deployed will get an IP address from the “production” pool. If we add the proper annotations to any new service that gets deployed, we can force it to use the wordpress IP address we specified.
Deploy WordPress
Let’s deploy a simple Wordpress blog using helm.
Add the Bitnami Helm Repository
helm repo add bitnami https://charts.bitnami.com/bitnami
Configure Wordpress
Here, I’ve put together a YAML file with just enough details to get it up and running. We’ll give it a title, a username, and details about our storage and load balancer service annotations. You should change any of these details as you need.
Install Wordpress with Helm
We’ll make a new “wordpress” namespace in k8s for this installation.
helm install wordpress -f wp-values.yaml --create-namespace wordpress \
--namespace wordpress bitnami/wordpress
This will spit out a whole bunch of text explaining how to find the randomly-generated password, the service IP address and more. Of course, we know it should pick up the IP address we defined for Wordpress in the MetalLB configuration. Grab the password via the commands provided.
Helm will create a whole bunch of resources, including a statefulset for MariaDB, a deployment for the Wordpress webserver, volumes for the database and wordpress web application itself, a secret to hold the generated password, and a number of other resources. This can take several minutes to complete. Feel free to open k9s again and watch the logs as MariaDB initializes, Wordpress waits to connect, and the entire provisioning process unfolds.
Once it’s complete, browse to the IP address you set up for Wordpress.
Use the admin URL and log in.
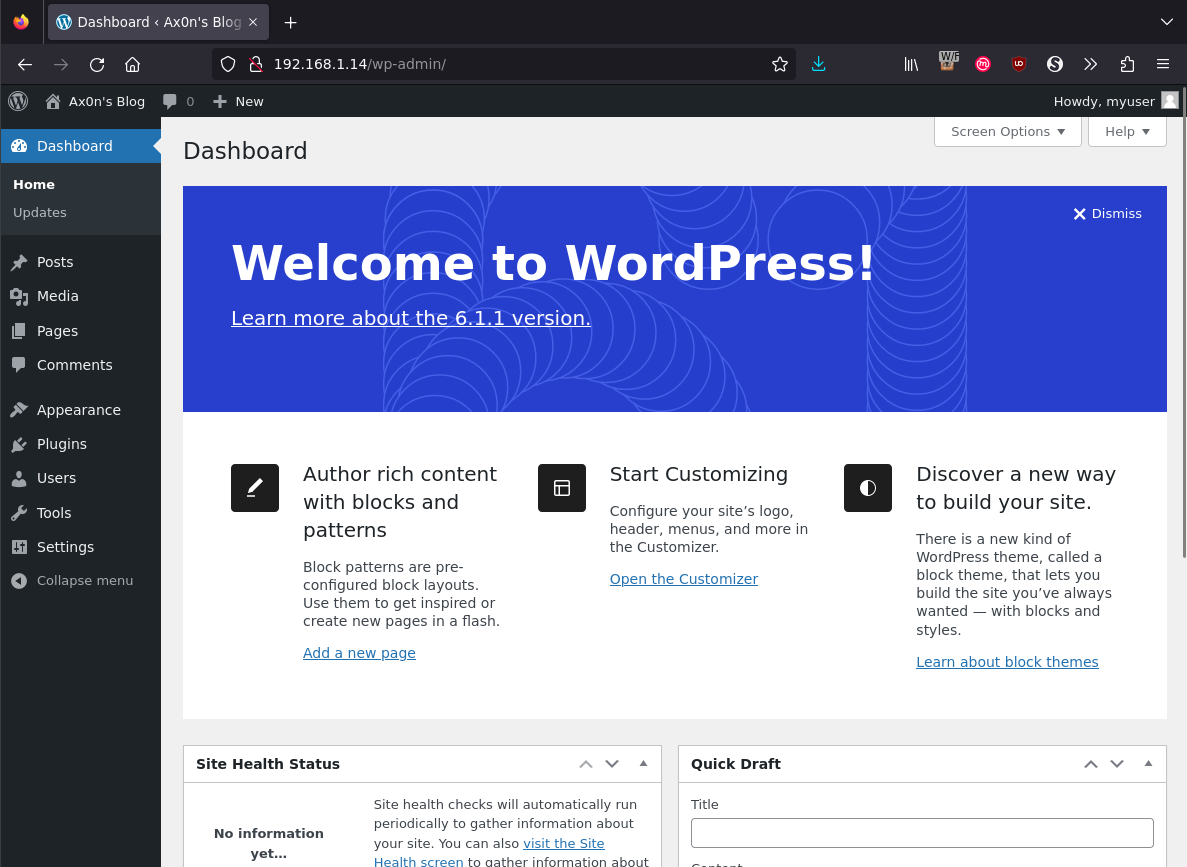
I did run into a well-documented issue with the installation, in that the health checks (readiness and liveness probes) caused the Wordpress container to restart before it was finished setting everything up. I had to manually create a “themes” directory inside my NFS server under the directory provisioned for wordpress and then manually download and set a theme inside the admin page. This seems to happen on lower-performance clusters. sometimes.
Subscribe to:
Posts (Atom)


